
Best of LLM Models for your use cases
Specific Models for Specific Usecase


Developing a Language Model (LLM) with broad applicability for general purposes offers a considerable challenge, as it requires addressing diverse linguistic nuances and contextual variations. Conversely, customizing existing LLMs for specific purposes offers a viable alternative, but it raises other challenges, like resource costs and datasets. Fortunately, some universities or communities have generated open-source LLMs that have emerged as valuable resources, showcasing impressive capabilities in specific domains.
We list down several open-source LLM models that focus on Healthcare, Mathematics, and Code generation. We break down the developer, the base model, the dataset, and the size, as well as how to access it.
Healthcare
Meditron
This is an open-source LLM with 7B and 70B parameters adapted to the medical domain developed by the Swiss Federal Institute of Technology. The Meditron utilizes the foundation of Llama-2 and expands its pretraining by blending a strictly curated medical corpus like selected PubMed articles, abstracts, and globally acknowledged medical guidelines. Assessments conducted on four prominent medical benchmarks reveal substantial enhancements in performance compared to various state-of-the-art baselines, both before and after task-specific fine-tuning. [see].

Even though the model already has good performance, it is not yet adapted to deliver this knowledge appropriately, safely, or within professional actionable constraints.
Try it: https://huggingface.co/epfl-llm/meditron-70b
Clinical Camel
This one is an open LLM which explicitly tailored for clinical research developed by Wanglab from the University of Toronto. The model is fine-tuned from LLaMA-2 using QLoRA, Clinical Camel achieves state-of-the-art performance across medical benchmarks among openly available medical LLMs. Leveraging efficient single-GPU training, Clinical Camel surpasses GPT-3.5 in five-shot evaluations on all assessed benchmarks [see]
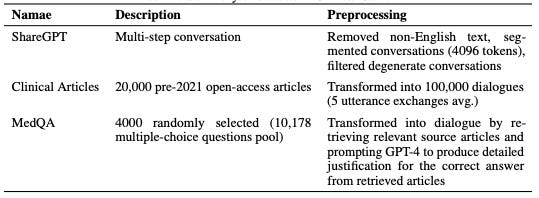
Clinical Camel introduces dialogue-based knowledge encoding, a novel method to synthesize conversational data from dense medical texts. The model surpasses several LLM like GPT-3.5 in five-shot evaluations. The model was trained on a diverse dataset which includes:
100,000 synthetic dialogues produced via dialogue-based knowledge encoding (DBKE).
10,187 USMLE questions which were converted via DBKE.
The ShareGPT dataset was also used, adding further diversity to the training data.
Try it: https://huggingface.co/wanglab/ClinicalCamel-70B
BioMedLM
This LLM model is developed by Stanford CRFM about a year ago. BioMedLM 2.7B is a new language model trained exclusively on biomedical abstracts and papers from The Pile. This GPT-style model can achieve strong results on a variety of biomedical NLP tasks, including a new state-of-the-art performance of 50.3% accuracy on the MedQA biomedical question-answering task. [see]

Try it: https://huggingface.co/stanford-crfm/BioMedLM
Mathematics
LLEMMA
This LLM has been built by EleutherAI on Code Llama: adaptation of Meta’s open-source Llama 2 model fine-tuned on code-specific datasets. The researchers developed two versions of the model, one with 7 billion parameters and another with 34 billion. The models were further fine-tuned on Proof-Pile-2, a dataset created by the researchers that is composed of a blend of scientific papers, web data featuring mathematics, and mathematical code.
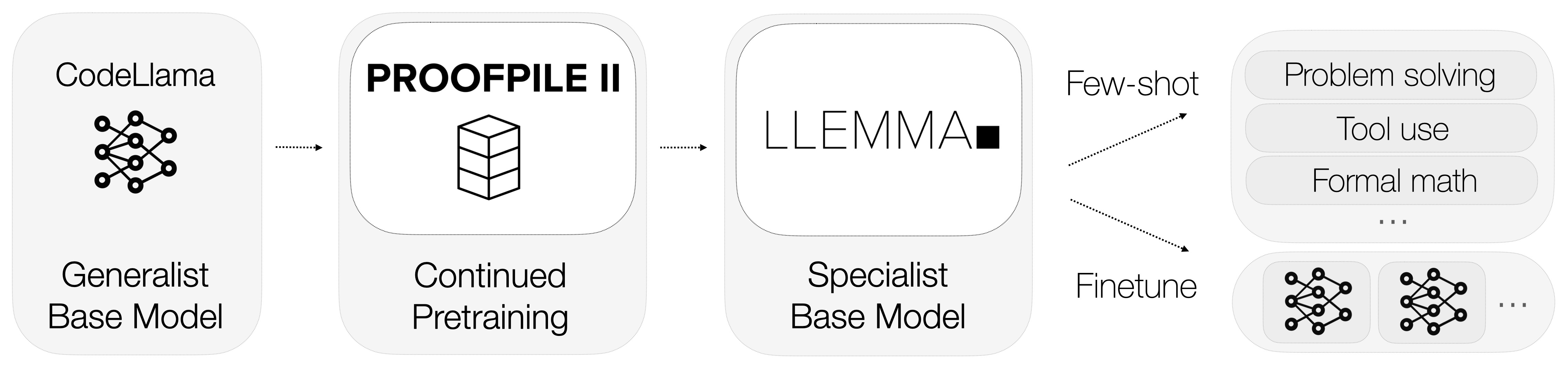
LLEMMA's remarkable adaptability is caused by its extensive pretraining on a wide array of mathematics-related data, enabling it to seamlessly transition between diverse tasks. The model's “creativity” is further amplified by its utilization of computational tools, including the Python interpreter and formal theorem provers. These tools empower LLEMMA with advanced problem-solving capabilities, allowing it to tackle complex mathematical challenges with precision and efficiency.
In comparison to Google's Minerva, LLEMMA stands out on an "equi-parameter basis," demonstrating great performance while also advocating for open-source accessibility. By surpassing Minerva in this regard, LLEMMA not only showcases its technical prowess but also emphasizes its commitment to fostering a collaborative and inclusive environment within the scientific-mathematical community. This dedication to openness and accessibility positions LLEMMA as a valuable resource for researchers and educators.

Try it: https://huggingface.co/EleutherAI/llemma_7b
MAmmoTH
This is a series of open-source large language models (LLMs) specifically tailored for general math problem-solving. The MAmmoTH models are trained by Tiger Lab at the University of Waterloo using Llama-2 and Code Llama. The model is built on the MathInstruct dataset, their own curated instruction tuning dataset. It presents a unique hybrid of chain-of-thought (CoT) and program-of-thought (PoT) rationales and also ensures extensive coverage of diverse fields in math. [see]
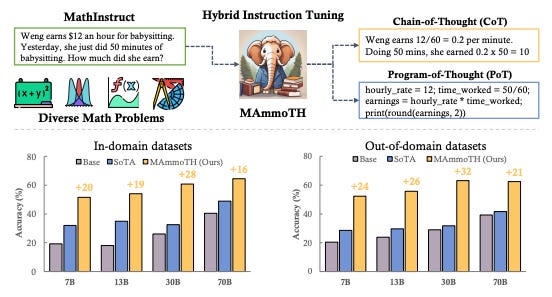
Try it: https://huggingface.co/TIGER-Lab/MAmmoTH-13B
Coding Co-pilot
DeciCoder
This LLM is developed by deci.ai using the Python, Java, and Javascript subsets of the Starcoder Training Dataset. The model is intended to do single/multiline code completion from a context window of up to 2048k tokens. It is not an instruction model and commands like "Write a function that computes the absolute value of an integer," won't yield the desired results.
Try it: https://huggingface.co/Deci/DeciCoder-1b#model-architecture
Code T5+
This model is developed by the Salesforce team with an encoder-decoder architecture that can flexibly operate in different modes (i.e. encoder-only, decoder-only, and encoder-decoder) to support a wide range of code understanding and generation tasks [see]. The model is pre-trained from scratch on the stricter permissive subset of the deduplicated version of the GitHub-code dataset.

This LLM Code generation supported 9 different languages as follows: c, c++, c-sharp, go, java, javascript, php, python, ruby.
Try it: https://huggingface.co/Salesforce/codet5p-16b
Conclusion
In conclusion, the exploration of fine-tuning models has demonstrated awesome performance in specific cases compared to their base counterparts. Moreover, the advocacy for open-source models, in contrast to closed-source alternatives like MedPalm by Google, underscores the collaborative and community-driven nature of knowledge advancement. Open-source models facilitate a shared pool of expertise, fostering innovation and problem-solving on a broader scale.
This model list, with its diverse applications, serves as an inspirational guide, encouraging all of us across various fields to embark on developing their open-source versions of Language Models (LLM). This approach not only empowers communities but also accelerates progress by embracing inclusivity and collective intelligence.