
Data Prepare of Basic Retrieval Augmented Generation
Basic RAG with Langchain in Local LLM -- TinyLLama


During my personal research in NLP last year, I encountered numerous articles guiding enthusiasts through the process of generating Large Language Models (LLMs) from the ground up or “fine-tuning” them on specific datasets. However, among those blogs and papers, I consistently ask: How can we seamlessly integrate our domain-specific knowledge, such as details about our restaurant or business, into these language models?
The solution lies in innovative approaches like Retrieval Augmented Generation (RAG), acting as a transformative bridge between general language models and domain-specific expertise. In simple terms, RAG operates as a universal plugin, facilitating the seamless integration of domain knowledge onto existing LLMs. In this article, my focus will be on the practical aspects of preparing documents for RAG, specifically leveraging Langchain to tidy the knowledge in the form of documents. Together, we'll explore the action of RAG compared with the main LLM with TinyLlama (see).
Introduction
The Idea of RAG is to Query the prompt within a vector store (like Chroma, Weaviate, or Faiss) and then merge the Query Result or we call it “context” with the original prompt before sending it to the main LLM. Therefore, RAG needs a vector store that contains vector embedding from parts of documents.
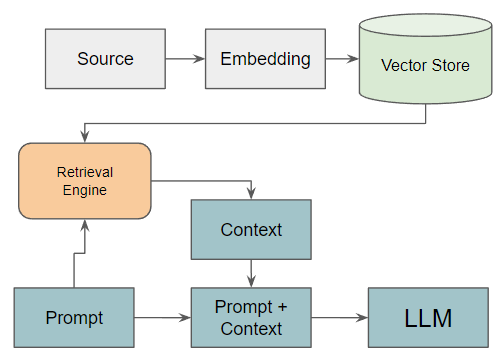
In a simple form, there are 4 parts in preparing the RAG: Document Loading, Document Splitting, Vector Store, and Retrieval. We will focus on the first three, then we’ll check the results of the main LLM and RAG LLM with the topic-specific prompt.
Pre-requisites
Hugging Face account — especially if you want to upload the source.
Local or Virtual Machine with at least 16 GB RAM.
Install Libraries
The tutorial here uses Python 3.9.18 with the requirement list here. The main libraries are:
langchain: a framework for developing applications powered by language models.
transformers: APIs and tools to easily download and train state-of-the-art pre-trained models.
fails-cpu: a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM
Datasets and LLM
For this tutorial purpose, I collect web pages about one topic in early 2024 which is not part of any current LLM data train. It’s the Noto Earthquake that happened on 1st January 2024. We are using Tiny Llama as our main LLM. We need to decide the LLM even during the beginning of preparation to determine certain parameters.
Document Loading
Imagine we want to use an LLM as our Customer Service Chatbot that knows about our product or services. Therefore we need the digitalized version “source” of this information about the product that may come from different types. In the first process, we must load the “source” into one object.
In this example, the “source” is 8 webpages from different websites that contain information about the Noto Earthquake that happened on 1st Jan 2024 (see). Firstly we put the URLs into the list object.
source_info = '../path/to/sources.txt'
all_webs = open(source_info)
all_webs = all_webs.readlines()
all_webs = [i.strip('\n') for i in all_webs]
The Langchain has a function AsyncHtmlLoader that can load URLs into the HTML text. After that, we can use another function Html2TextTransformer to extract the page content from HTML.
from langchain_community.document_loaders import AsyncChromiumLoader, AsyncHtmlLoader
from langchain_community.document_transformers import BeautifulSoupTransformer, Html2TextTransformer
# Load HTML
loader = AsyncHtmlLoader(all_webs)
all_html = loader.load()
# Extract Contain of HTML
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(all_html)The docs_transformed at the end is a list of Document objects — A Document is a piece of text and associated metadata (see). For some reason, possibly because of the paywall, we only successfully loaded 7 out of 8 of the URL pages above into Document.

If there are other formats of “source”, Langchain provides different document loaders for variants of formats like CSV, JSON, PDF, and Markdown (see).
Document Splitting
The next step after the data is loaded, transforming the data into a suitable form for the LLM or application. In our case, we want to split the document to fit our TinyLlama model number of tokens. In our case, we are using RecursiveCharacterTextSplitter (see) to do this splitter which needs parameters like chuck size and chuck overlap. For now, we use 400 tokens with the assumption we just need the first 3 of context from the vector store as input on top of the original prompt (so the maximum length will be around 1200 tokens for context input to TinyLlama).
from langchain.text_splitter import RecursiveCharacterTextSplitter
from tqdm.auto import tqdm
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=50, # number of tokens overlap between chunks
# length_function=tiktoken_len,
separators=["\n\n", "\n", " ", ""]
)
documents_chk = []
m = hashlib.md5() # this will convert URL into unique
for doc in tqdm(docs_transformed):
url = doc.metadata['source']
m.update(url.encode('utf-8'))
uid = m.hexdigest()[:12]
chunks = text_splitter.split_text(doc.page_content)
for i, chunk in enumerate(chunks):
obj = {
'page_content': chunk,
'metadata': {
'id': f'{uid}-{i}',
'source': url
}
}
obj = Document(**obj)
documents_chk.append(obj)The results of the script above are document_chk — another document list, which contains the chunk of our document from docs_transformed previously.
Vector Store
In the last part, before the retrieval, we transform the list of chunks above into an embedding vector. We can use any good embedding model, in this case, we use all-MiniLM-L6-v2 (see).
from torch import cuda
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
embed_model_id = 'sentence-transformers/all-MiniLM-L6-v2'
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'
embed_model = HuggingFaceEmbeddings(
model_name=embed_model_id,
model_kwargs={'device': device},
encode_kwargs={'device': device, 'batch_size': 32}
)The embed_model is an object that transforms sentences into embedding. For example:
embed_model.embed_query("just testing") --> [0.01,-0.41,..,0.101,-0.037]Once the embedding model is ready, create the vector stores to store all embedding related to all of the chunks. There are 583 chunks with 384 dimensions of embedding, the store is relatively small — less than 2 MB. There are many options for vector stores, in this example, we are using FAISS (Facebook AI Similarity Search). It is a library that allows developers to quickly search for embeddings of multimedia documents that are similar to each other.
from langchain_community.vectorstores import FAISS
vdb = FAISS.from_documents(documents, embed_model)
vdb.save_local("../path/to/save/vdb_faiss_index")We do an example query to the vector store as follows,
## Testing
question = "what is Noto earthquake?"
searchDocs = vdb.similarity_search(question)The vector store returns several chunks of documents that relate to that query. Here is the number one top result from the vector store:
Quake damage on the Noto Satoyama Kaido, a highway that runs the length of Noto Peninsula in Ishikawa Prefecture. | JIJI
Main LLM vs RAG LLM
Once the vector store is ready, we can do retrieval that connects the vector store to Tiny Llama. It’s an easy connect in Python use RetrievalQA from the Langchain. Firstly load Tiny Llama into basic_llm and also vector store into vstore then combine them with RetrievalQA.
## Load Tiny Llama
from torch import cuda
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline, AutoModelForQuestionAnswering
from langchain.llms import HuggingFacePipeline
model_id = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'
langchain_tg = pipeline(
model=model_id,
tokenizer=AutoTokenizer.from_pretrained(model_id),
return_full_text=True, # langchain expects the full text
task= "text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
# we pass model parameters here too
temperature=0.0,
max_new_tokens=512,
repetition_penalty=1.1
)
basic_llm = HuggingFacePipeline(
pipeline=langchain_tg
)
## Load Vector Store
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
embed_model_id = 'sentence-transformers/all-MiniLM-L6-v2'
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'
embed_model = HuggingFaceEmbeddings(
model_name=embed_model_id,
model_kwargs={'device': device},
encode_kwargs={'device': device, 'batch_size': 32}
)
vstore = FAISS.load_local("../path/of/vdb_faiss_index", embed_model)
## Combine
from langchain.chains import RetrievalQA
rag_llm = RetrievalQA.from_chain_type(
llm=basic_llm, chain_type='stuff',
retriever=vstore.as_retriever()
)
## Asking same question to both
basic_llm(prompt="what is Noto Earthquake?")
rag_llm("what is Noto Earthquake?")The basic_llm response that there was a Noto Earthquake in 2019 with a 7.2 magnitude. However, there is no such information about the earthquake anywhere (see). It is expected the LLM will return bad information, but instead of returning “We don’t have enough information” it returns hallucination information (see).
basic_llm:Noto Earthquake was a 7.2 magnitude earthquake that occurred on August 16, 2019, in the Pacific Ocean off the coast of Japan.
Meanwhile, our rag_llm return “almost” correct information about the Noto Earthquake. The response is beautifully crafted, it tells us the definition of the Noto Earthquake, the date, the location, and the magnitude. However, It says the earthquake happened on 4th January instead of 1st January 2024. This could happen because of several factors like unclean document or insufficient chunk. But overall, it is still much better than the basic llm above.
rag_llm:The Noto Earthquake was a series of earthquakes that occurred along the Noto Peninsula in Japan on January 4, 2024. It was caused by the Noto-Sakurazaka fault zone rupturing, resulting in a magnitude 7.6 earthquake and tsunami. The earthquake caused significant damage to buildings and infrastructure, including the Noto Satoyama Kaido highway, which runs the length of the peninsula.
Common Issues
Chunk Not Correct
There are possibilities that the chunking of the docs is not correctly implemented.
Different Language
There could be different languages in a document
Standardize Date and Time
The date and Time format of our source may not be suitable for LLM.
Works with number
Same as the date, the number format could also not align with what LLM trains with.
Conclusion
Retrieval Augmented Generation is the solution to plugin our domain knowledge to any LLM. It is easy to set up and, with the right machine, gives faster results without any fine-tuning. However, inconsiderate preparation on the source will jeopardize the RAG pipeline results. In summary, collect all related sources, clean it up, then create a vector store and we are good to do retrieval with any LLM.
Insightful as usual