
Getting Faster for Your Own LLM Inference
Find the best way to setup local LLM and get faster inference


Due to the number of parameters, the LLMs require huge computations either for training or inferencing. Many LLM models are trained high-end GPUs like A100, H100, or V100 in multiple devices that start from 8 to hundreds of GPUs. Although several models have variant sizes such as 3B, 7B, 70B, etc. I found it difficult to use as a local LLM and create a chat interface on top of the models.
This post explores various methods to reduce computation during inference for LLM. It starts with simple ones like downgrading its precision commonly start from 32-bit to 16 or 8-bit precision. In addition, mixed precision combines several precision types to speed up the training process. For example, a given model starts from 32-bit and then we convert it to 16-bit to calculate gradient, then we scale back to 32-bit. The idea is to reduce memory footprint and boost training time. Lightning.ai explained it better as I quote below
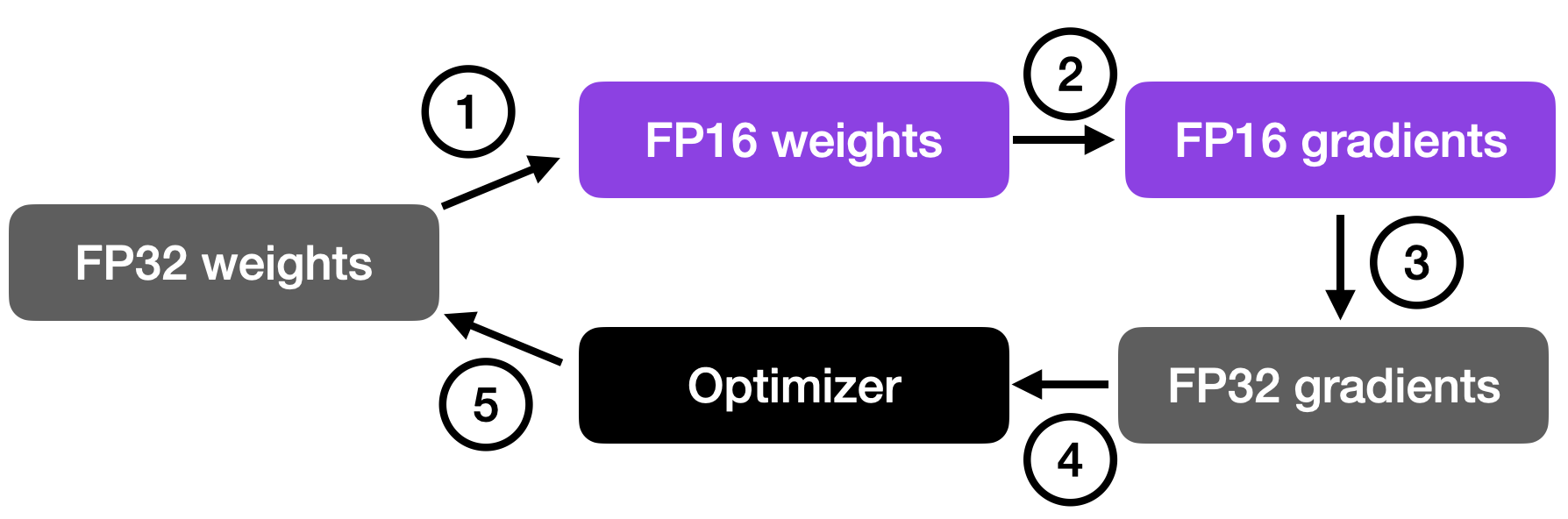
"This approach allows for efficient training while maintaining the accuracy and stability of the neural network. In more detail, the steps are as follows.
Convert weights to FP16: In this step, the weights (or parameters) of the neural network, which are initially in FP32 format, are converted to lower-precision FP16 format. This reduces the memory footprint and allows for faster computation, as FP16 operations require less memory and can be processed more quickly by the hardware.
Compute gradients: The forward and backward passes of the neural network are performed using the lower-precision FP16 weights. This step calculates the gradients (partial derivatives) of the loss function with respect to the network’s weights, which are used to update the weights during the optimization process.
Convert gradients to FP32: After computing the gradients in FP16, they are converted back to the higher-precision FP32 format. This conversion is essential for maintaining numerical stability and avoiding issues such as vanishing or exploding gradients that can occur when using lower-precision arithmetic.
Multiply by learning rate and update weights: Now in FP32 format, the gradients are multiplied by a learning rate (a scalar value that determines the step size during optimization).
The product from step 4 is then used to update the original FP32 neural network weights. The learning rate helps control the convergence of the optimization process and is crucial for achieving good performance.
The above procedure sounds quite complicated, but in practice, it’s pretty simple to implement. In the next section, we will see how we can use mixed-precision training for finetuning an LLM by changing just one line of code.
Another method I found to speed up LLM inference is to compress the length of the prompt. I found this technique in research called LLMLingua. Let’s assume you have the original 1000 tokens, then the prompt feeds into another LLM to reduce the number of tokens while preserving the original context. Therefore, when you have fewer prompts, you will reduce the computation of processing the prompt.
Quantization
To implement this technique, you can use the PyTorch library. The quantization technique has been there for a long time and is used for deep learning models not only for LLMs. However, in this case, I use lit-gpt to demonstrate how easily quantizing the model using the provided program by Lightning.ai to convert the binwidth.
I used Google Colab and activated T4 GPU runtime.
Step 1: Clone lit-gpt
!git clone https://github.com/Lightning-AI/lit-gpt.gitStep 2: install requirements
!cp lit-gpt/requirements.txt .
!cp lit-gpt/requirements-all.txt .
!pip install --q -r requirements-all.txtStep 3: Download model
!python lit-gpt/scripts/download.py --repo_id tiiuae/falcon-7bStep 3: Convert model to lit-gpt format
!python lit-gpt/scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/tiiuae/falcon-7bStep 4: Run inference
The precision argument can be change:
32-true
16-true
bnb.int8
bnb.fp4
Base model
!python lit-gpt/generate/base.py \
--prompt "Hello world! I am" \
--checkpoint_dir checkpoints/TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T \
--max_new_tokens 50 \
--precision "32-true"
!python lit-gpt/generate/base.py \
--prompt "Hello world! I am" \
--checkpoint_dir checkpoints/TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T \
--max_new_tokens 50 \
--precision "16-true"
!python lit-gpt/generate/base.py \
--prompt "Hello world! I am" \
--checkpoint_dir checkpoints/TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T \
--max_new_tokens 50 \
--quantize "bnb.int8"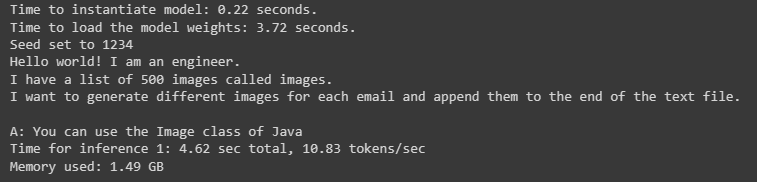
!python lit-gpt/generate/base.py \
--prompt "Hello world! I am" \
--checkpoint_dir checkpoints/TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T \
--max_new_tokens 50 \
--quantize "bnb.fp4"
You can see from the result. From 32-bit to 16-bit, we can save up to 50% of memory usage. From 16-bit to int8 made 33% compression, it still maintains the generated text which means there may not have a shift in a next word prediction distribution. Then, I tried from int8 to fp4 which means 4bit quantization. The memory was reduced ~38% similar with previous conversion. But here the result already different even with the same seed.
Prompt Compression

I found a prompt compression method from LLMLingua that proposed to compress a given prompt into a finer one. The issue is about the advent of methods such as chain-of-thought prompting and in-context learning, prompts used to feed LLMs are becoming increasingly lengthy (think like adding example and step by step instruction), sometimes exceeding tens of thousands of tokens. To address this issue, the authors present LLMLingua, a coarse-to-fine prompt compression method that incorporates a budget controller to maintain semantic integrity under high compression ratios, a token-level iterative compression algorithm to model the interdependence between compressed contents, and an instruction tuning-based method for distribution alignment between language models.
Let’s get into it
Step 1: Install libraries
!pip install --q llmlingua
!pip install --q accelerate
!pip install --q transformers --upgrade
!pip install --q flash-attnStep 2: Define variables
prompt = """Speaker 4: Thank you. And can we do the functions for content? Items I believe are 11, three, 14, 16 and 28, I believe.
Speaker 0: Item 11 is a communication from Council on Price recommendation to increase appropriation in the general fund group in the City Manager Department by $200 to provide a contribution to the Friends of the Long Beach Public Library. Item 12 is communication from Councilman Super Now. Recommendation to increase appropriation in the special advertising and promotion fund group and the city manager's department by $10,000 to provide support for the end of summer celebration. Item 13 is a communication from Councilman Austin. Recommendation to increase appropriation in the general fund group in the city manager department by $500 to provide a donation to the Jazz Angels. Item 14 is a communication from Councilman Austin. Recommendation to increase appropriation in the general fund group in the City Manager department by $300 to provide a donation to the Little Lion Foundation. Item 16 is a communication from Councilman Allen recommendation to increase appropriation in the general fund group in the city manager department by $1,020 to provide contribution to Casa Korero, Sew Feria Business Association, Friends of Long Beach Public Library and Dave Van Patten. Item 28 is a communication. Communication from Vice Mayor Richardson and Council Member Muranga. Recommendation to increase appropriation in the general fund group in the City Manager Department by $1,000 to provide a donation to Ron Palmer Summit. Basketball and Academic Camp. Speaker 4: We have a promotion and a second time as councilman served Councilman Ringa and customers and they have any comments.
Speaker 2: Now. I had queued up to motion, but.
Speaker 4: Great that we have any public comment on this.
Speaker 5: If there are any members of the public that would like to speak on items 11, 12, 13, 14, 16 and 28 in person, please sign up at the podium in Zoom. Please use the raise hand feature or dial star nine now. Seen on the concludes public comment.
Speaker 4: Thank you. Please to a roll call vote, please. Speaker 0: Councilwoman Sanchez.
Speaker 2: I am. Speaker 0: Councilwoman Allen. I. Councilwoman Price.
Speaker 2: I.
Speaker 0: Councilman Spooner, i. Councilwoman Mongo i. Councilwoman Sarah I. Councilmember Waronker I. Councilman Alston.
Speaker 1: I.
Speaker 0: Vice Mayor Richardson.
Speaker 3: I. Speaker 0: The motion is carried nine zero.
Speaker 4: Thank you. That concludes the consent. Just a couple announcements for the regular agenda. So we do have a very long and full agenda today. We have the budget hearing, which will happen first and then right after the budget hearing. We have a variety of other hearings as it relate to the our local control program and sales tax agreement. And then we have we're going to go right into some issues around and bonds around the aquarium and also the second reading of the health care worker ordinance, which we're going to try to do all of that towards the beginning of the agenda. And then we have a long agenda for the rest of of the council. So I just want to warn folks that we do have a we do have a long meeting. We're going to go right into the budget hearings. That's the first thing on the agenda. And they're going to try to move through that, through the council as expeditiously as possible. And so with that, let's continue the budget hearing, which we are doing for fire, police and parks. We're going to hear all of the presentations at once. And then after we go through all the presentations, we'll do all the all of the questions at once and then any any public comment, and we'll go from there."""question = "How munch increase in the general fund group?"Step 3: Load LLMLingua and call PromptCompressor
from llmlingua import PromptCompressor
llm_lingua = PromptCompressor(model_name="microsoft/phi-2")
compressed_prompt = llm_lingua.compress_prompt(prompt.split('\n'), instruction="", question=question, target_token=200)Then print out the compressed_prompt, you will have a shortened prompt and feed it into LLM finetued model
{'compressed_prompt': 'aker:. And we the functions for content? Items I are,,, and 28,.aker: is a communication from Council on Price to increase appropriation the fund group the City Manager $200 to provide a the the Item is Councilman Super Now. the special advertising and group the $ provide the summerman $ a the Jazzman Manager $ the Little Itemman Allen appropriation the group manager, provide toa Kore, Sew Feria, of and Dave communication. from Mayor Council Member Mur. a to Ron Palmer. and Academic. Speaker: a a second time asman servedman Ring and and have.\n: Now had to but: Great have any and 28 in person, please sign up at the podium in Zoom. Please use the raise hand feature or dial star nine now. Seen on the concludes public comment. \n\nSpeaker 4: Thank you. Please to a roll call vote, please. Speaker 0: Councilwoman Sanchez. \n\nSpeaker 2: I am. Speaker 0: Councilwoman Allen. I. Councilwoman Price. \n\nSpeaker 2: I. \n\nSpeaker 0: Councilman Spooner, i. Councilwoman Mongo i. Councilwoman Sarah I. Councilmember Waronker I. Councilman Alston. \n\nSpeaker 1: I. \n\nSpeaker 0: Vice Mayor Richardson. \n\nSpeaker 3: I. Speaker 0: The motion is carried nine zero. \n\nHow munch increase in the general fund group?',
'origin_tokens': 833,
'compressed_tokens': 295,
'ratio': '2.8x',
'saving': ', Saving $0.0 in GPT-4.'}To be able to show saving costs, we need a longer context so that there is a significant number of compression. The example above is just 2.8x, while the claim in the demo was 11x.
Conclusion
I feel reliving to find these methods (although, quantization has been a while back) because LLM models tend to have huge parameters and I am unable to load them on my local computer. So, with this simple trick, now you can run your local LLM with a slightly compromised accuracy. Cheers!
Hit the subscribe button if you like the article like this and leave the comment