

Unearthing Datasets Preparation for LLM
Your LLM success starts from Good Datasets Preparation


LLM is Everywhere
Since I read about the Chatgpt that was released in late 2022 (see), I saw the research and articles about text generation and LLM have increased significantly. As AI enthusiasts, I believe all of us have: followed the news, forked on the related repo (because of the open source), and tried fine-tuning those LLMs locally. But not all of us do it successfully. Maybe because the infrastructure is not enough or the model parameters are not tuned correctly. One other reason that perhaps missed to be observed is the dataset preparation.
Dataset impacts LLM
Starting the journey of language models (LM), I find myself focused on the peak of research spanning information theory, machine learning, speech processing, and natural language processing. Those various disciplines make LM results more robust and adaptable, powering an array of applications. Within this expansive landscape, Large Language Models (LLMs) stand out, distinguished by their shocking multitude of parameters of neural network architectures. The core of their training lies in utilizing extensive datasets, representing a departure from conventional approaches and opening doors to the domain of text generation (see).
At the heart of LLM’s success lie the critical elements of Datasets and Model Architecture. In our LLM development process, we carefully overlook and refine each of these components independently. Dataset complexity and variety can impact the performance of the LLM in several tasks or particular contexts. The model architecture will influence the inference latency and the number of acceptable token inputs on the same altitude of importance.
As we delve into the developmental process, we focus on the Datasets phase. This involves the collection of diverse and representative datasets, followed by a careful curation process to filter and refine the data. Afterward, we prepare datasets, setting the token size for the model to learn and generalize effectively. In this exploration, we will unravel the complication of the Datasets aspect, navigating through the nuances of collection, curation, and preparation within the context of LLMs.
Preparation is The Key
I’ve found out that like many other LMs, in general, there are two parts to training LLMs in any industry context to generate text.
The first part is Pretraining the model in which the task is predicting the next word given a series of words.
The second part optimizes the model for certain tasks. Most of the LLM is trained to generate text given input/question. The rest use LLM for spam detection, (still on) sentiment analysis, or summarization.
In either of those processes above, the preparation of the data is important. Imagine the huge amount of the corpus for pretraining LLM full of deduplication. Or the dialogue datasets contain short answers only and not the correct ones. These cases impact the model performance in evaluation later on. There are at least three subsections to preparing the datasets for LLM: Corpus Collection, Corpus Cleansing, and Model Input Preparation.
Corpus Collection
This is the very first step of your LLM from scratch process. We need a Corpus to create any Language Model. What is Corpus? based on Merriam-Webster, a Corpus is all the writings or works of a particular kind or on a particular subject (especially: the complete works of an author.). In other words, the corpus is a collection of writing like novels, stories, news, Wikipedia, chats, papers, posts, or Blogs.

One way (not the only way) to create a Corpus (or Corpora for plural) is by scrapping it through the internet. In the LLM case, the Cospus needs to be large, quality, and diverse. Recent work has demonstrated that increased training dataset diversity and quality improves general cross-domain knowledge and downstream generalization capability for large-scale language models. the corpora can be general text or domain-specific, such as multilingual data, scientific data, and code, to give LLMs specific problem-solving abilities. There is a source that is already collecting corpora examples for LLM here both for pretraining and dialogue optimization.
If the corpora list above is still not enough, we always have the option to do scrapping on our own. However, this process is not as easy as it sounds. Regarding scrapping, we must also be concerned about ethical principles and guidelines. This includes Respecting Terms of Service, Obtaining Consent, Avoiding Overloading Servers, Respecting Privacy, and Compliance with Laws and Regulations.
Corpus Cleansing
The effectiveness of the LLM will heavily be driven by the quality of the data input, and as many articles mention: Garbage In Garbage Out. Once we obtain a comprehensive corpus, we must clean up the mess inside the data. Particularly when it comes to scraping data from the internet, which often introduces challenges such as typographical errors, misspellings, and the inclusion of HTML-related tags like "<header>". This process ensures consistency and eliminates anomalies that will contribute to optimal model performance.
After carefully checking the spelling and unnecessary punctuation, we should do text normalization specifically on,
Replace Contractions: like using cannot instead of can’t
Expand the Abbreviations: like changing “Dr.” to Doctor. We may focus on this on domain-specific text.
Normalize Numbers format: like replace “3201,0” with “3,201.0”
Remove Stopwords: In general, there is no need to remove stopwords for LLM if we want to do Text Generation. But it will be helpful if there is offensive terminology.
Stemming or Lemmatization: This will be useful for not text generation tasks.

Lastly, the collected corpus is so large that it may contain Personal Identifiable Information (PII), like name, address, email, telephone number, passport number, or fingerprint. On top of that, the corpus also may not vary enough and it carries sentences that have the same meaning or even the same. Corpora with those conditions must be Anonymized and Deduplicated. Anonymize corpus simply finds PII data and removes it or masks it before doing the train. Meanwhile, deduplication tries to reduce levels of duplication and information redundancy (see). There are several ways to do deduplication, such as MinHash, Locality Sensitive Hashing, SimHash, or as simple as Removing Repetitive unusual words. However, as a note, Deduplication does not always reduce LLM performance. Repeating data intelligently and consistently may outperform the baseline model (see).
Model Input Preparation
In the final preparation (before LLM pretraining), we must transform the string data above into smaller parts and then convert it to numbers which is usually called Tokenizing. There are multiple ways to tokenize text:
Word Tokenization
Subword Tokenization
Characters Tokenization
Special Token
Additionally, models like GPT-3 use special tokens to indicate prompts and responses in a conversation.

Since the model usually has fixed input, we must determine how many tokens should be set for the text transformation. For relatively small LM, we can use hundreds or millions of tokens, but for LLM it can be Billions or Trillions (see). The more of the tokens, usually the better the model. However, the larger the model leads to a longer training time.

Furthermore, after the pretraining LLM is done, the input preparation will depend on the task. For example, in sentiment prediction, we just simply create a pair of input text and output labels as the data train to the model (as classical supervised ML usually has). Meanwhile, for Text generation, we must create the data input into sequence-to-sequence format as we want to do the translation tasks.

Dataset Constrain
Collection and Cleaning datasets for LLM is not as easy as it sounds. Within this detailed process, numerous limitations come into play, demanding careful consideration and strategic navigation.
Infra Cost: Infrastructure for data collection and any big text data preparation process must be huge and complex. The complexity leads to a big cost in this process.
General purpose: By itself, a large language model cannot perform specialized or business-specific tasks. For example, we can’t use ChatGPT as the company’s chatbot as it was not trained on your products or services. Unless we finetune the model into the company’s dataset.
Data Bias: LLMs are prone to bias, which affects their response's accuracy and appropriateness. This may result in costly unfair predictions in security, finance, and other mission-critical industries. It’s essential for us to carefully analyze the dataset for biases related to gender, race, culture, and other sensitive attributes. Mitigation strategies such as debiasing techniques and diverse dataset curation should be employed.
Abused: Models like GPT can be abused or misused without additional regulations. As pre-trained models, they might respond with inappropriate text, outdated information, or made-up facts.
Privacy Concerns: Text data can often contain sensitive or private information. It’s important to anonymize and sanitize the data to protect user privacy. We must adhere to data protection regulations and guidelines is a must.
Author Acknowledge: In this era, it is easy to collect data text by crawling the web. However, the collector most likely ignores the author of those texts. Since we will use this data for LLM training, we must acknowledge the author and better get a permit from them.
Example Studies
There are several studies about how different data preparation will impact the LLM performance. In one study (see), they learned that deduplication affects the performance of trained models for Global or Local deduplication. Global Deduplication means decreased duplication based on different corpora. Meanwhile, in local deduplication, duplicates are removed within each source dataset before merging them. On top of that, increasing data diversity is crucial after global deduplication.

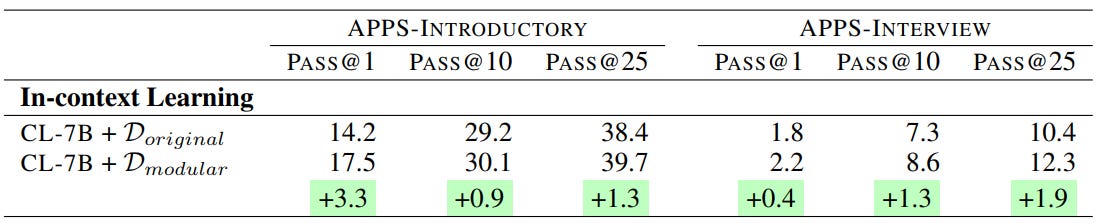
In the other study (see), the code generation LLM-based has a better performance using the Modularized dataset which is cleaner and more structured. They build a novel data-cleaning pipeline that uses several principles to transform existing programs like renaming variables, and modularizing-decomposing complex code into smaller helper sub-functions. The transformed modularized programs improve the performance by up to 30% compared to fine-tuning on the original dataset.
Conclusion
In a nutshell, the LLM landscape is buzzing with research, and the excitement is only bound to grow. However, one crucial factor that stands out like a hero behind the scenes, the data input preparation. Without careful attention to data collection, text normalization, and text tokenizer, these LLMs wouldn't perform well. Those processes provably shortened the training time, minimized bias, and boosted in overall performance. But, it's not all sunshine and rainbows; we've got to keep an eye on the backstage issues like cost, data bias, privacy concerns, and giving credit where credit is due to the authors. So, as we dive deeper into the future of LLMs, let's not forget, that behind every impressive model, there is a foundation of well-prepared data.