
Cart Recommendation with VectorDB
Simple Implementation VectorDB in Python


In the dynamic landscape of AI Generation, VectorDB has emerged as a crucial tool, with implementations such as RAG facilitating the way for advanced applications. The significance lies in its ability to accelerate searches within high-dimensional vectors, exceeding traditional limitations in various domains. Whether dealing with images, texts, products, or detecting user fraud, the transformative power of VectorDB becomes evident when these entities are converted into vectors. The capability to utilize VectorDB for retrieving similar vectors based on any query associated with a given entity emphasizes its impact across diverse fields, positioning it as an essential asset in the realm of artificial intelligence.
Introduction
Let a supermarket have data from the past about every customer's cart. They want to use the data as the base to create a recommendation system. They also need the system to not only correct but also fast. In the real use case, given a cart item list of the customer, the supermarket wants to offer item recommendations to the customer so they can increase sales.
VectorDB is one of the answers to the problem statement above. We will break down the process of how VectorDB can recommend items based on the cart item list using Python. Start from how we transform the data into a vector space, then store it in VectorDB. Lastly, check the performance of the recommendations using Average Precision.
Pre-requisites
Local or Virtual Machine with at least 16 GB RAM.
The demonstration is using Python 3.9.18
The main Python libraries of this example are Pandas, Numpy, Annoy
Data and Proposed Solution
In this demonstration, we assume the supermarket has the cart data of past transactions. It must contain the user_id, order_id, item_type, and item counts. We are using the data in here which is the simple version of the instacart data here. For simplicity, we are using “Departement” of items that user pick in their cart instead of the item name itself. So, we expect to suggest other departments to the user given their cart list.

There are at least 2 parts to create the recommendation system using VectorDB. One is the creation of the VectorDB including vector creation and vector indexing. The second part is the retrieval and post-process of the retrieval. Here are the detailed steps of the proposed solution to the problem above:
Creation
Create user embedding (or the vector) based on their previous cart
Store the embedding into VectorDB — which is also called vector indexing
Retrieval
Transform the user cart into a vector — make sure the vector query and the vector in the VectorDB are in the same vector space.
Retrieve similar vectors from the VectorDB
Use the retrieval vectors to generate the recommendation
Vector Generation
This simple demonstration will generate the embedding of each user using a simple algorithm utilizing their previous order. Suppose user x has N orders and each order must have k department with n_i item count of department i. In our case, we have 18 department items, so each order must have 18 sequences of numbers. The image below illustrates user “82654” has 8 orders :

In this format, we can normalize —The Normalization Method— the item count of each department with the total items of the order. We can say the result of this normalization is the Order level embedding. For example, if the order has 3 departments with several items number: 1, 2, and 2, then the normalization would be 1/5, 2/5, and 2/5 respectively. Then the User Embedding is the average of this normalization of the user orders.
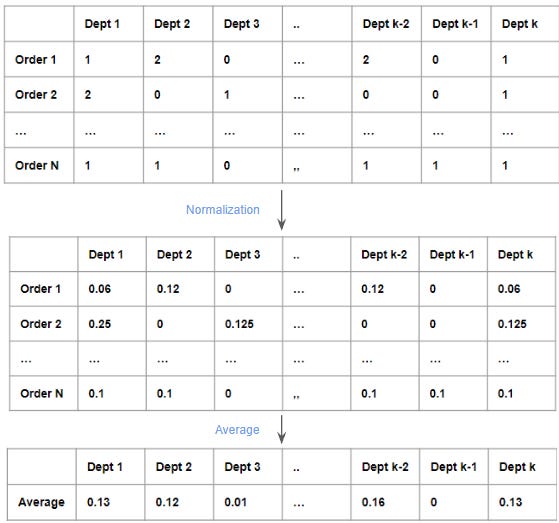
We loop the process through all users from the data. Remember to split the data into train and test based on the user split. We have around 149.556 users for train and these users have done orders at least 3 times. Since there are only 18 departments in the data, each user embedding has a dimension length equal to 18.
entity_cols = [list of department name]
users_embedding = df_train.groupby("user_id")[entity_cols].mean()
users_embedding.sample(15)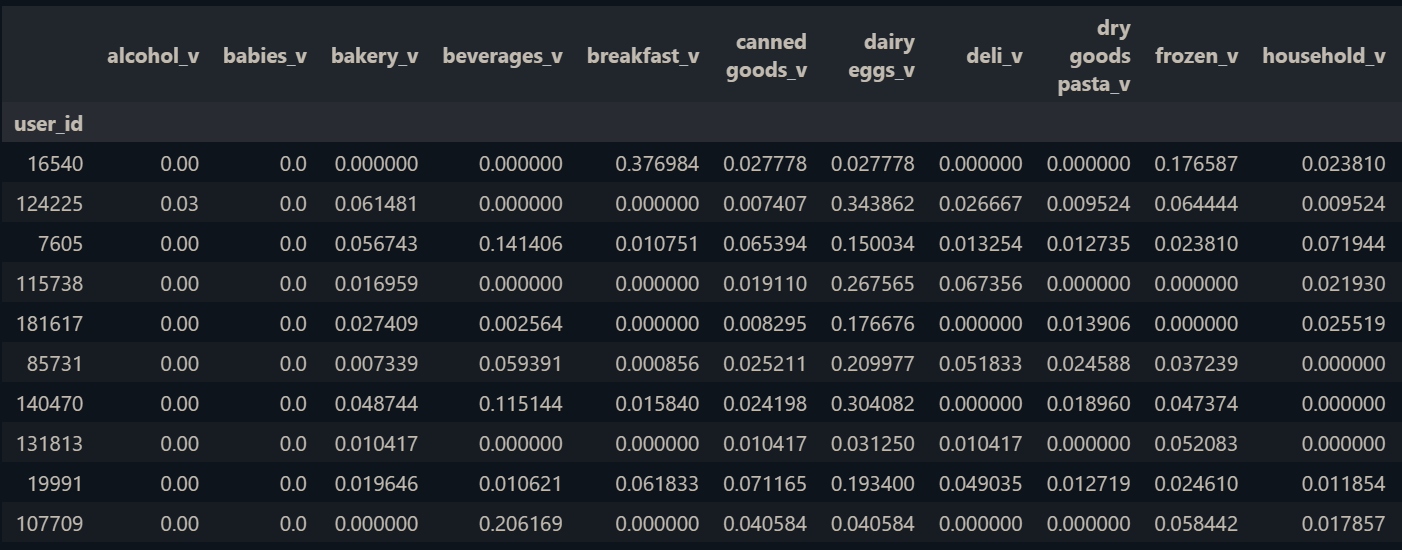
The Vector Indexing and Retrieval
In this demo, we use Annoy as the VectorDB. The following code easily generates and saves the VectorDB Annoy to store the user embedding from the previous section. We denote vdb as the VectorDB object.
Keep reading with a 7-day free trial
Subscribe to The Beep to keep reading this post and get 7 days of free access to the full post archives.