

Key Components to Understand the LLM Models
Llama 2, Mistral, and GPT-3 with its components original transformer, rotary positional embedding, sliding window attention


A Primer
The rise of large language models starts with natural language processing and understanding tasks that aim to solve specific tasks such as text classification, token classification, and word similarity up to the model that generates free text such as text summarization, language translation, and question answering.
The language model predicts the next word of the given input words, you can think the application is for autocomplete. The early approach to this task uses statistical methods such as the Markov chain to predict the probability of the next word. Later, the development moved forward for language models using neural networks such as RNN and LSTM to predict the next word. The neural language model gives a significant leap toward an end-to-end solution for NLP and NLU tasks. At the same time, embedding was introduced for word representation from the language model.
The pre-trained language model is a term for a general language model that is trained on self-supervised tasks such as next-word prediction or cloze word prediction and then later the pre-trained model needs to be fine-tuned on the specific downstream task. Pre-trained language models are like ELMo, BERT, and BART.
Large language models as the name suggests “Large”, is similar to the pre-trained language model but it scales the parameters and dataset size. By scaling the parameters and dataset sizes, the research finds specific abilities that are not found in the pre-trained language model, this is called “emergent abilities” such as in-context learning.
In-context learning, also called few-shot learning, is a technique used in large language models. Imagine teaching a robot new tricks with just a few examples instead of lots of lessons. Traditional machines need tons of practice, but with in-context learning, you only show a few examples, and the model learns to do new things on its own without training the model or changing its weights.
LLM Models Method Dependencies
I read some of LLM papers such as Llama2, Mistral, and GPT-3. I tried to unpack all the methods that were used in the paper so that I can understand the differences between the models and I believe the models are far different from the original implementation. So, I created a list of methods used in the LLM models. I break down per section for each model. So you can dig down deeper for every method.
Llama2
Based on Llama-1
Based on Transformer architecture
Pre-normalization using RMSNorm [GPT-3]
SwiGLU activation function [PALM]
Rotary Positional Embeddings
BytePair Encoding (BPE) using SentencePiece
Grouped-query Attention (GQA)
https://blog.briankitano.com/llama-from-scratch/
Mistral
Based on Transformer
Grouped-query Attention (GQA)
Sliding Window Attention (SWA)
FlashAttention
xFormers
Pre-fill and Chunking, Rolling Buffer Cache1
GPT-3
Based on GPT-2
Transformer
Sparse Transformer
Below, I explain briefly about the method, and I hope this can give you a picture how what the method looks like.
Rotary Positional Embeddings

Rotary Positional Embedding is one of the positional embeddings that have been recently and popularly used by many large language models such as PaLM, Llama, and Mistral. The embedding is a combination of absolute and relative positional embedding that is introduced in the original Transformer and T5.
Rotary Positional Embedding solves the problems in the absolute and relative positional embedding where the issue of absolute positional embedding is there is a limit on how long the length of the token can cover e.g. 512. Another one is positional embedding that learned vectors, there is no definitive meaning of the vector position between positions 1, 2, and 100 in which we hope that position embedding 1 and 2 should be close compared to 1 and 100. The issue of relative positional embedding is that you have to modify the attention mechanism in a way that the dot product of Q and K is added to the bias of relative embedding.
The process of rotary positional embedding is quite simple:
Initialize the embedding dimension
Calculate the theta

Calculate the matrix cos and sin

or to put it simple matrix multiplication

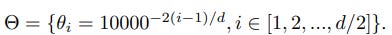


Transformer

All large language models such as Llama, GPT-3, and Mistral, use transformer architecture for their models. A transformer is an architecture that follows an encoder-decoder format. The input is fed into the encoder network and the decoder generates the output based on latent space from the encoder network.
There are a lot of layers inside transformers. We tried to unpack here:
Input Embedding
Positional Encoding
The Encoder Network consists of
Multi-head Attention
Add & Norm
Feed Forward
The Decoder Network consists of
Masked Multi-head Attention
Add & Norm
Multi-head Attention
Feed Forward
Linear
Softmax
Grouped-query Attention (GQA)
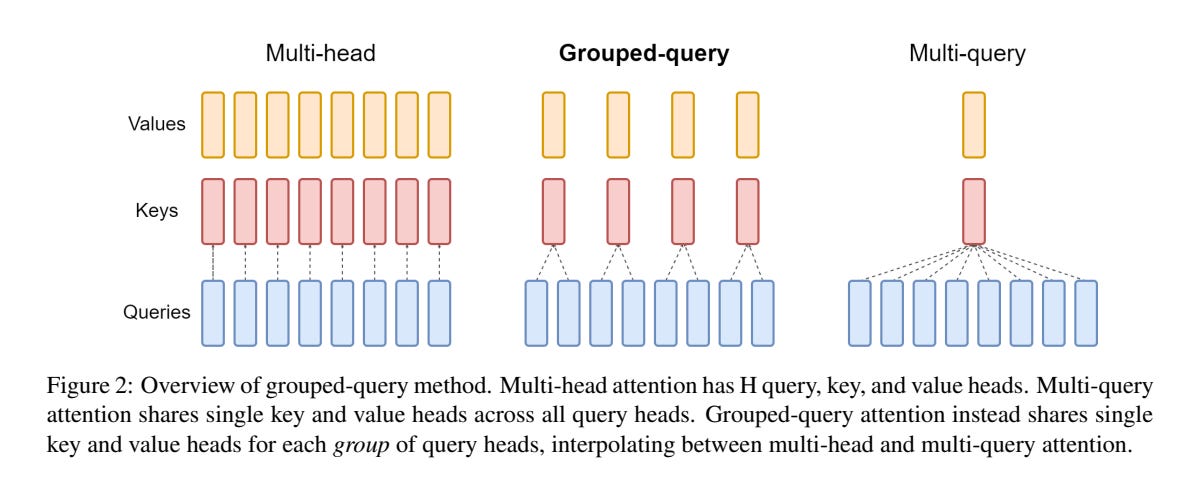
Grouped query attention (GQA) is a technique used in transformer-based neural network models that aims to speed up the decoder inference process. GQA offers in-between Mutli-head Attention (MHA) quality as well as the speed of Multi Query Attention (MQA). The approach is quite simple, given a pre-trained model of MHA, we will take the number of G for the key and value. If G=1, it equals the MQA, and if G=# of Heads then it equals MHA. GQA is only applied to the decoder's self-attention and cross-attention.
Grouped-query attention divides query heads into G groups, each of which shares a single key head and value head. GQA-G referes to grouped-query with G groups.

GQA uses mean pooling to make a group for the keys and values. Imagine you have 12 attention heads and the groups are 3. Then you calculate the mean pooling of 4 heads to form a single group. I assume that each query will be applied to a certain group in the order of query. So, the query heads of 1 up to 4 are applied to the first group key and value, 5 to 8 are applied to the second group of the key and value, and so on.
Sliding Window Attention
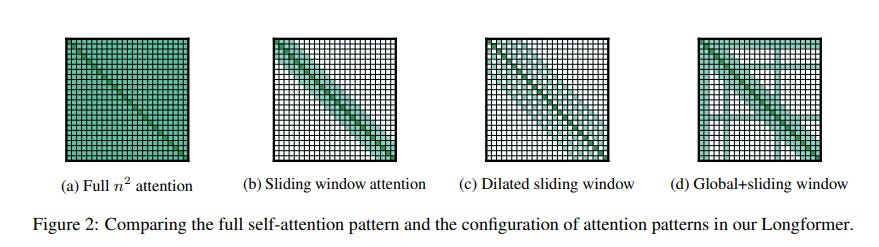
Sliding window attention is introduced in the Longformer paper, which aims to address the issue in the Transformer that is unable to process long documents due to self-attention operation which scales quadratically with the sequence length.
The concept is to divide the sequence into smaller windows of a fixed size and then apply an attention mechanism to each window separately. This allows the model to focus on the relevant context within the window and ignore the irrelevant context outside the window.
The sliding window is then moved across the entire sequence, processing each window in turn. The output from each window is then combined to generate the final result. This approach is useful for tasks that require processing long sequences of text, such as machine translation, document translation, and question answering, as it allows the model to handle long sequences more efficiently and avoid out of memory.
I hope this post helps you to grasp the concept around LLM and its key components.
Additional Reading
original from Mistral AI